OmniSAT: Compact Action Token, Faster Auto Regression
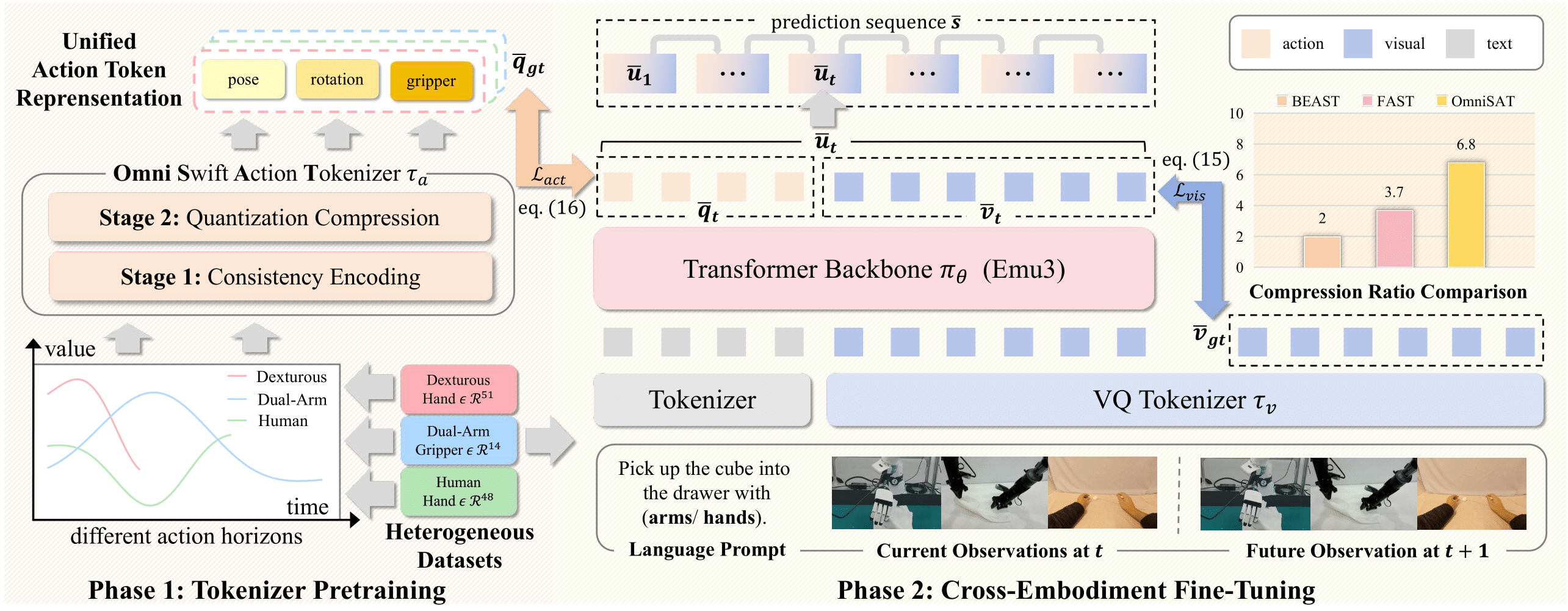
Comparison between Existing Approaches and OmniSAT
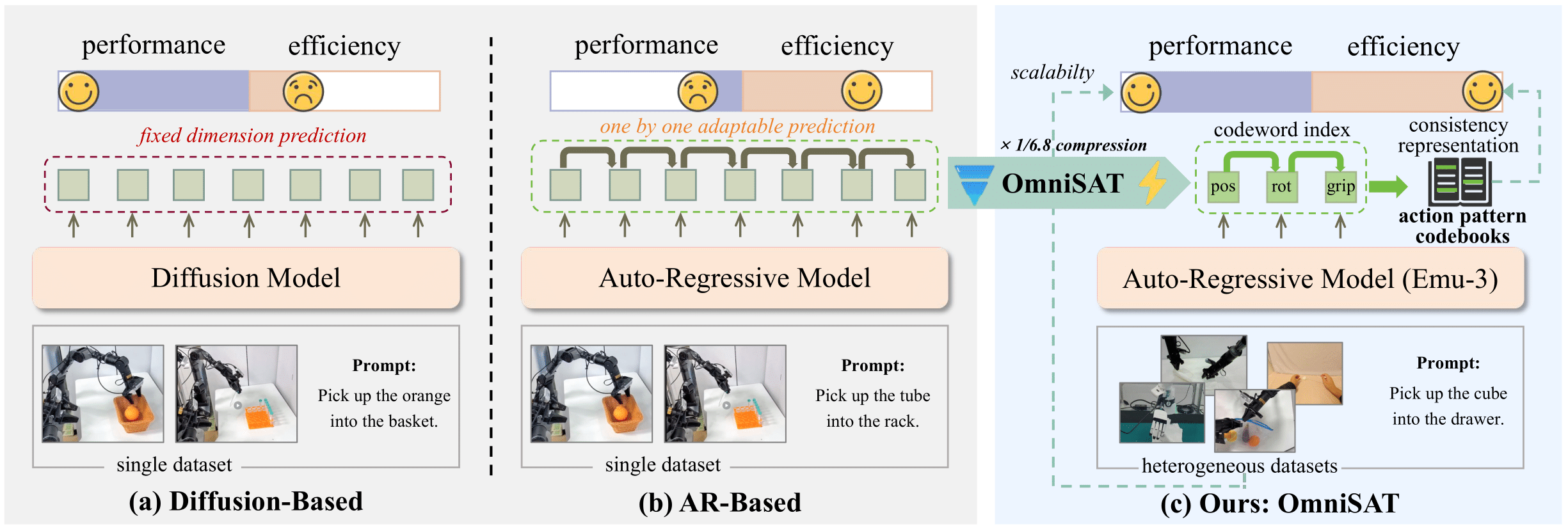
Abstract
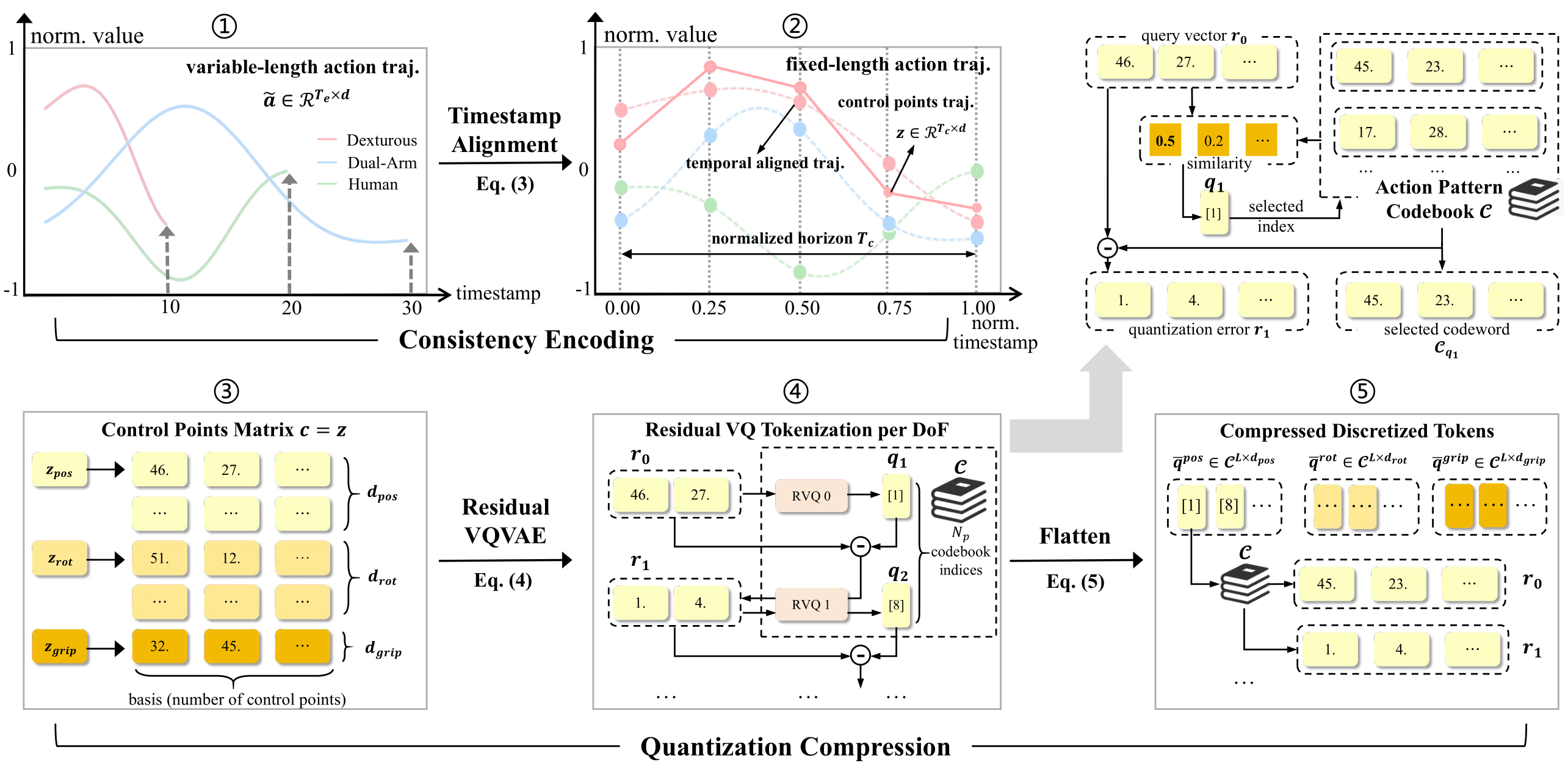
Existing Vision-Language-Action (VLA) models can be broadly categorized into diffusion-based and auto-regressive (AR) approaches: diffusion models capture continuous action distributions but rely on computationally heavy iterative denoising. In contrast, AR models enable efficient optimization and flexible sequence construction, making them better suited for large-scale pretraining. To further improve AR efficiency, particularly when action chunks induce extended and high-dimensional sequences, prior work applies entropy-guided and token-frequency techniques to shorten the sequence length. However, such compression struggled with poor reconstruction or inefficient compression. Motivated by this, we introduce an Omni Swift Action Tokenizer, which learns a compact, transferable action representation. Specifically, we first normalize value ranges and temporal horizons to obtain a consistent representation with B-Spline encoding. Then, we apply multi-stage residual quantization to the position, rotation, and gripper subspaces, producing compressed discrete tokens with coarse-to-fine granularity for each part. After pre-training on the large-scale dataset Droid, the resulting discrete tokenization shortens the training sequence by 6.8×, and lowers the target entropy. To further explore the potential of OmniSAT, we develop a cross-embodiment learning strategy that builds on the unified action-pattern space and jointly leverages robot and human demonstrations. It enables scalable auxiliary supervision from heterogeneous egocentric videos. Across diverse real-robot and simulation experiments, OmniSAT encompasses higher compression while preserving reconstruction quality, enabling faster AR training convergence and model performance.
Real-world Experiments
PlaceObj
TubeRack
ZipSeal
OmniSAT Tokenization Pipeline
OmniSAT for Cross-Embodiment Manipulation Learning